A case against inline agents
- Tags:
- syntax
- eiffel
- code quality
Context: Programs as documents
An Eiffel program is a complex data structure. It is made out of attributes, local variables, types, classes, instructions, feature calls, assignment attempts and a lot more. These constructs reference each other: attributes are used by features, features contain instructions, instructions use local variables, local variables reference types, types are built from classes, and so forth.
When we look at the textual representation (the code text) of an Eiffel program, we identify two major ways that these relations are expressed.
Here, the
The second way to express these relations is by the use of identifiers. Identifiers are arbitrary words (with a few limitations, for example they must not be the same as a keyword) that allow references to other parts of the code text. For example:
The local variable definition uses the identifier
These two ways of expressing relations in a program have a direct effect on how we write compilers to read in code text from a file. It done in two steps.
The first step – understanding references through the use of textual context – is called the syntactial analysis of a programm, using a scanner and a parser. The result is a tree, called the abstract syntax tree.
The second step is called the semantic analsysis of a program (I always found the word syntax and semantics very missleading in this context, as both parts establish the structure of the code, and the second part has nothing to do with what that code actually means). The semantic analysis enriches the abstract syntax tree node with references to other tree nodes, creating the actual graph that defines the program.
This blog article is about the code text and its way to express the abstract syntax tree, as established during syntactic analysis. We are looking at it from the perspective of a human coder who has to read the text, not from that of a compiler that has to parse it.
Textual representations of Trees
Developers use screens (I am talking about the physical thing in front of you) to develop code. A screen allows the display of a 2-dimensional image. The code text is a linear sequence of characters, but with the introduction the NEWLINE character, it can be broken into individual lines. This way, code text has a 2D representation, using both dimension on the screen.
Now there is a challenge: how can we layout the program as a 2D text in such a way that it is easy for the developer to see the underlying abstract syntax tree, thus making it possible for the developer to understand the program?
In general, there are two ways this is done: indentation and bracketing.
Using indentation, we distribute the nodes of the abstract syntax tree over the rows in the text, each node on a new line. We do this in a depth-first fashion, by first writing the parent node, and then the child nodes. The child nodes are then indented in relation to the parent. Here is an example:
The
The second way of expressing the tree structure is by the use of bracket pairs. A bracket pair are two symbols or keywords that together mark the beginning and end of a set of sub-nodes in the tree. Examples of bracket pairs are the paranthesis
The use of paranthesis makes it clear that
A tree defined using bracket pairs is much harder to understand than a tree using indentation levels. It requires the human eyes to scan the complete line, to recognise individual characters and words, and to have a mental “stack†counting how many opening and closing brackets we have seen.
Most trees expressed in bracket pairs become confusion after a few levels. This is even true for paranthesises, even though we are highly trained to spot these pairs from years of math training in school.
So, why not use indentation for everything? We could write the expression above using (for example) the following:
We do not do it, because vertical real-estate is precious and programs written this way would become very long, which has its own problems with readability. If we are able to keep the numbers of brackets low, the use of brackets is a very compact way of expressing trees, growing horizontally instead of vertically.
Most modern programming languages (including – with one exception – Eiffel) do the following: they use bracket pairs as the prime element to express tree properties, but allow the free use of newlines and spaces (known as whitespace) to express the tree structure through the use of indentation.
The language comes with a strong culture on how to indent, even though the developer is allowed to deviate from these rules (most of the time to prevent a line from becoming too long, or to write compact code). The culture makes code readable between different developers.
Levels of the AST
When looking at tree structures, we can look at the recursion points, that is tree composition rules that allow the creation of recursive structures by containing themselves.
There are two main recursion structures in Eiffel (as in most other programming languages): instruction and expression.
Instructions contain the imperative part of the programming paradigm; they describe the computation by state transformations. Recursion is caused by rules for sequences, conditionals and loops.
Expressions contain the functional part of the programming paradigm; they describe the computation by function evaluations and their return values. Recursion is caused by the rules for function arguments.
Eiffel (with the exception of inline agents, discussed below) does not allow expressions to contain instructions. This always causes the syntax tree to have the following form:
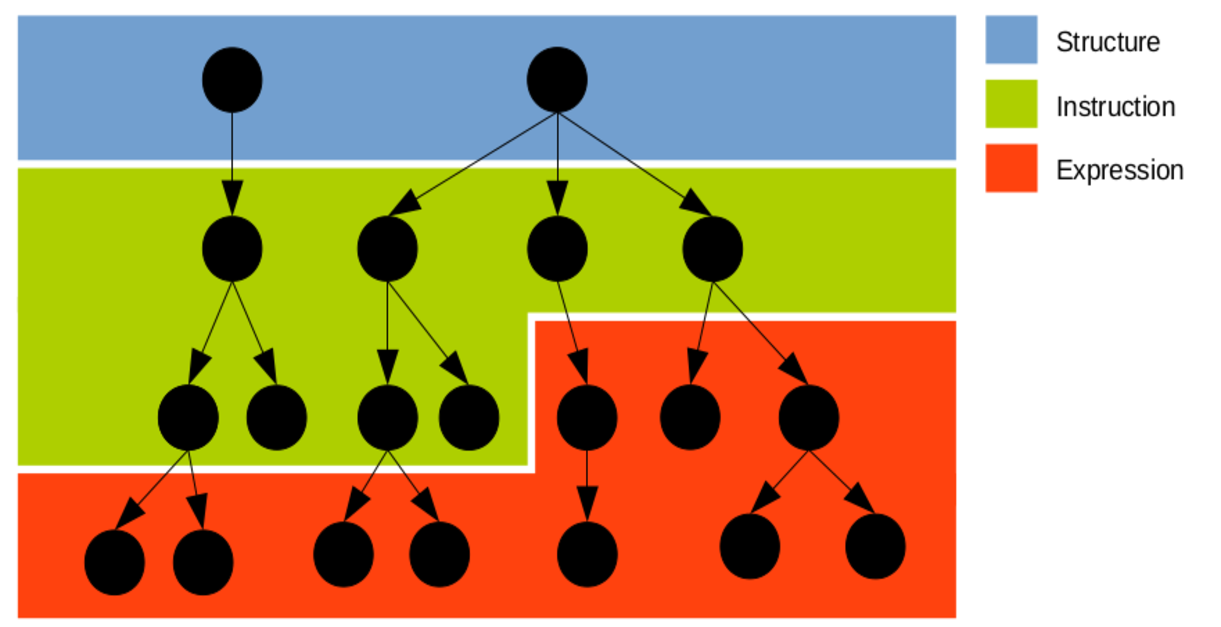
The imperative paradigm and the functional paradigm are very different, each one having it's own set of challenges to the human brain. One of the challanges of programming language design is to find the right balance and relation between the two.
Eiffel, using option/operand and command/query separation, emphasises the use of instructions over the use of expressions. Data-structures have built-in cursors. The number of arguments to feature calls are minimized.
This has a huge advantage: we can use the indentation purely for the imperative portion of the code. With expressions small, we have no problem using brackets to structure them, keeping them compact. The imperative control flow of the program is not interrupted by lines that are only continuations of the expressions from previous lines.
For the reader of the program, this is not only elegant: together with the rejection of return statements and other “hidden GOTOsâ€, the structure of an implementation becomes clear immediately. Code is easy to change, problems are easy to spot.
Criticizing Inline Agents
Inline agents allow instructions to appear in expressions. This breaks the invariant that expressions are always below instructions in the tree. Instead, we now have the ability to freely switch between instructions and expressions while going down the tree, resuling in the following structure:
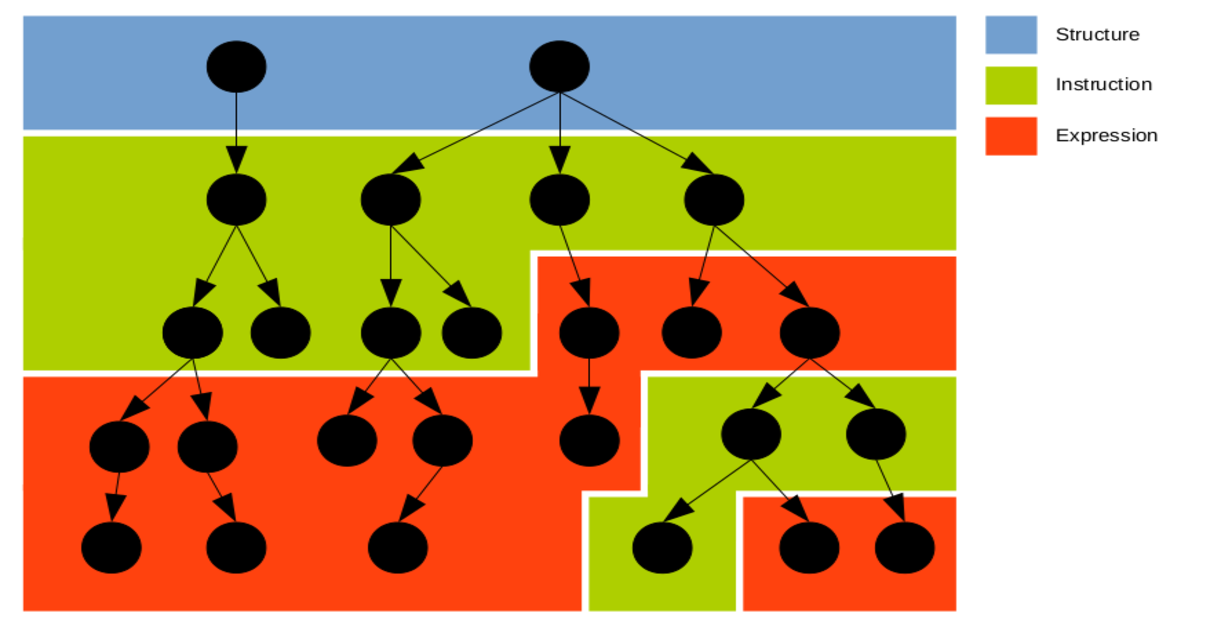
This has severe consequences for the structure and layout of the program. It starts with the obvious problems that indentation rules now are completely thrown overboard. It becomes unclear how to indent the inline agent. If we write
then we are wasting a huge amount of space in front of the feature. Considering that horizontal scrolling is more tedious than vertical scrolling, this can make the code very unreadable. Also, it violates the guideline that expressions should be short and single lines.
On the other hand, if we write
then we obfuscate the fact that the agent is indeed a parameter to the
The second criticism of inline agents is the fact that we are loosing an important element of structured programming: the indention of a feature visualizes the structure of the underlying algorithm. This structure is now “polluted†with control flow of inline agents, which are code that is not actually executed as part of the routine, but might be executed much later.
Summary
This show article illustrates my main concerns with inline agents for the control flow and the readablity of the programming language.
It is clear to me that inline agents are very dangerous to structured programming and to clean code. We have to understand how they can undermine our efforts to produce a culture of code that is highly readable, one of the main advantages of using Eiffel.
Whenever advocating the use of inline agents, we are not doing us a favor. There might be cases where the inline agent can produce more readable results and compact code. But in the long run, they are not going to improve the programming language.
I agree. And secondly, you can't override inline agents. We could have done without inline agents in Eiffel perhaps. Obviously it can be used judiciously, and with power comes responsibility and all that. And we want to write terse code.
Agents in general
Perfectly true point, redefinitions are not possible for inline agents. Though it is possible to redefine the feature that defines the agent.
There is something fundamentally non-object-oriented in with agents in general, which goes much deeper than my article. There are no classes to abstract them, no contracts to add, no way to subtype or inherit. That would be another article ...
Inline agents: tree structure, type inference and code reuse
After reading Bernd's article yesterday, I thought it was time for me to give my feeling about inline agents. Like many people, I find them too verbose, and therefore they are harder to read in the class text. Bernd's well-written article showed that in a clear manner. Type inference is an attempt to address verbosity. Although type inference could become a fantastic help if used by EiffelStudio to auto-complete types, I personally don't think that it is a good idea to consider class text as valid as soon as the compiler can infer the missing type. As a human reader, the missing types will make the code more difficult to understand. And to come back to inline agents, type inference and agent composition in my opinion do not provide enough simplification to make inline agents really usable.
Let me explain what my ideal inline agent would look like, and in which cases I would really need them. So far we had regular agents, something like:
c.do_all (agent f)One problem that I would like to be addressed is that in the case of an agent with two or more open operands, if the existing featuref' has the arguments in the wrong order, we have to write another featureg':g (a:A; b: B) require .... do f (b, a) ensure ... end c.do_all (agent g)Wrting this kind of feature `g' is in my opinion a waste of time for the programmer. It's a disruption in his work. What about inline agent?c.do_all (agent (a:A; b: B) require .... do f (b, a) ensure ... end)Even when removing the assertions, it's not really attractive. If I'm not mistaken, with type inference the code would look like:c.do_all (agent (a, b) do f (b, a) end)This is not quite yet what would make inline agent attractive enough for me to use them. In this particular case, for me the most attractive alternative is the one already suggested by Colin Adams a long time ago:c.do_all (agent f (?2, ?1))It's clear, terse and simple. We could even imagine some variants like:c.do_all (agent h (?2, ?2))where an operand is repeated.Colin has one argument that I think is true about inline agents: they go againts code reuse. Indeed if we have code like that:
c.do_all (agent (a:A; b: B) do f (b, a) d := foo h (d, 1) ... end)there is a good chance that the code in the inline agent could be useful in some other part of the program. In any case, putting this code in a proper routine gives the opportunity to provide a header comment, useful assertions, etc. And as already pointed out, it allows redefinition in descendant classes. So in which cases would I find inline agents useful? This is in cases where I want to pass a single expression. Here is an example:c.for_all (agent {A}.is_valid)This looks great. All items inc' are valid. But what about if I want to express that all items inc' are not valid, and there is no featureis_not_valid' in the third-party class A? Writing a featureis_a_not_valid' in the current class seems overkill. It does not belong to the current class anyway but to class A. But again, it looks overkill to have in class A:is_valid',is_not_valid',is_valid_and_successful',is_valid_but_not_successful', ... Using an inline agent as we know them today, or type inference and agent composition do not look attractive to me either. Ideally, what I would want for inline agents is something like that:agent Inline_agent_expressionwhere Inline_agent_expression is like Expression but augmented with open operands. For example:c.for_all (agent not {A}?1.is_valid)Then it's up to the compile to build the auxiliary feature:g (a: A): BOOLEAN do Result := not a.is_valid endWe could also have:c.for_all (agent successful ({B}?2) and then {A}?1.is_valid)One thing that I often want to write as well is something like that:c.do_all (agent f (?.foo))If I use the same kind of language extension, it would look like that:c.do_all (agent f ({A}?.foo))and the compiler would build the auxiliary feature:g (a: A) do f (a.foo) endIn other words, in order for inline agent to be attractive, I think that the syntax should be as simple as possible (even simplier than with type inference, using ?1, ?2, etc. instead of declaring formal argument names), and the body should limit itself to a single instruction or expression (like across expressions). Everything else should be encapsulated into a proper feature to benefit from code reuse, redefinition, assertions, etc. and then accessed using regular agents.Inline agents only expressions
Hi Eric, you are absolutely right. One point that you mentioned is the introduction of Inline_expression agents. So, instead of allowing all kinds of agents to be defined inline, we only would allow FUNCTION agents to be created inline, with the agent itself only consisting of a single expression describing the Result.
This would cover us for many cases where we want to use inline agents for contracts, while at the same time prevent all the problem that I described above.
In general, I think there are three main problems which are solved with agents. Instead of developing a single approach to cover them all, it might be better to come up with different solutions:
I think we have to go through each one of these uses independently, to come up with a good solution. If we try to discuss these points in one go, I think we will waste a lot of time.
Inline expression agents with normal parameters list
I like the idea of inline agents reserved for expressions, it seems the most common use of lambda expressions in python and works well. But I'm not convinced by the question mark syntax. It feels un-Eiffelish to me, why not simply have a normal parameter list, like in Python and many other languages with lambdas?
or with more than one argument:
it also solves another problem of the question mark syntax, that recursive inline agents have to either be banned or ambiguous, while they work fine with named parameters:
A validity constraint should require the parameters to be unused in the context (in the example, it would be illegal for the second agent's paremeter to be called 'inner_c'), that is in upper agents, but also locals, top level routines parameters, or class features.
Of course, recursive agent expressions could quickly be abused, but so can normal expressions, which can include subexpressions without limits, so the problem belongs to style guidelines.
This syntax is also compatible with type annotations either optional or mandatory:
this without using the inline {A} type notation that I've never liked being used in feature bodies.
On type inference more generally I'm fine with it inside routines.
I once read the argument that we already have type inference anyway (was for Java, but it's the same for us):
is the same as:
a.foo.barand somehow we managed to infer the type of "a.foo"...
To apply that consistently without losing the local variables declaration altogether -- it does prevent some typos and it's nice to have all locals visible before starting with the body of a routine -- a possible solution would be to require the local declaration, but not the types:
which makes it similar to inline expression agents parameters.
Where are the extra parameters coming from?
You show an agent with two parameters, but for_all only delivers one. What is going to bind b?
Examples
That is the evil thing with mocked-up examples ;-)
Simpler inline agents
I think taht inline agent was mainly created to have more expressive contacts (quantification expressions with
for_all' andthere_exists'). And more they are often used for simple expressions in the routine body. Thus, I agree fully the idea to allow only inline agents as expression.@Eric
According me the proposed syntax is a bit ugly...
I don't know if it is necessary to introduce the question mark index, i.e.agent f (?2, ?1) . A lot of eiffel routine are argumentless or with only one argument.
However if inline agent are reserved only for expression, it could be usefull.
@Franck
The functional proposals go in this direction. i.e.agent (a) then expression end
with `a' inferred.
This syntax is more Eiffelish... However I prefer this one:agent (a) do expression end
The use of a verb (`do') is a bit disturbing, however the unity is kept.
AN advantage to use
then' could be to forbid the use oflocal' with. Thus, you will use[local ...] do' orthen' to define a feature. But in the current proposalthen' can be placed afterdo'.Not more expressive
They are no more expressive than ordinary agents.
Contracts
Like what Eric said in his comment, my usage of inline agents is for code massaging. Some routine expects an agent with a specific signature and I have to change it.
The work we are doing at the moment with type inference can simplify the syntax for agents and inline agents, even covering some of the proposals made in comments.
However, I think my main concern is not so much with inline agents but contracts with agents. I'm reading too much code where someone will write
agent fand pass it to some action sequence in Vision. However the code offwill look like:f (arg: ARG) require arg_valid: arg.is_valid do .... endwhich doesn't make sense because Vision is not assuming any preconditions on agents. Thus passing
agent fis incorrect.This is what I would like us to work on more.