My three Eiffelwishes, part 2: Unicode
- Tags:
- Unicode
If English is your primary language, you've probably never used characters from a foreign language in Eiffel source files. Perhaps you'll be interested in this little experiment then: create a classic "Hello, world" program and run it, then replace the string with its translation in, say, arabic, and run it again.
The classic "Hello, world" program:
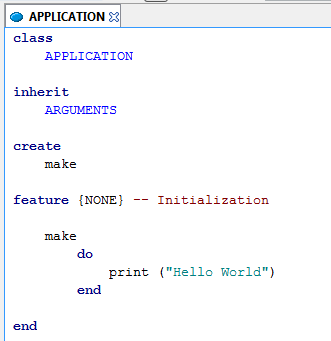
Running the program:

The modifed program with a translated string:
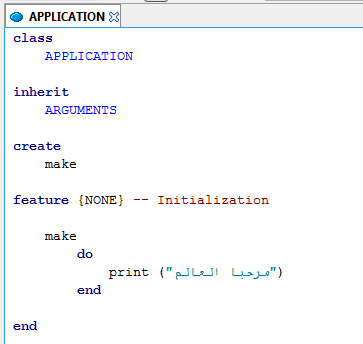
Running the modified program:
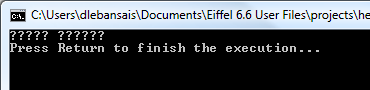
As you can see, the result is not exactly the expected one. The reason is simple: EiffelStudio doesn't store characters as unicode, but rather in ASCII format. What you see in the modified text code is a display artifact, and not the string as stored in the source file. Just close and reopen the class text to make this clear. Arabic characters have been lost.
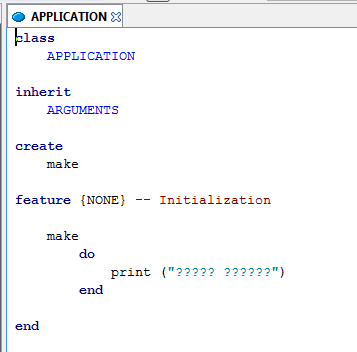
Unicode
Unicode is a standard for storing and manipulating characters from pretty much all languages around the world, including ancient languages that appear only in old texts. The first version of the standard was published in 1991.
Unicode isn't a file format. To store unicode text, an editor has several options, but ASCII isn't one of them and for this reason editors that manipulate ASCII files will not read or write unicode text correctly. This is what's happening with EiffelStudio.
Benefits of unicode
If EiffelStudio could fully support unicode, there would be several benefits for programmers.
Comments
A comment written with characters that don't belong to the ASCII set can be stored and read properly by people using the same language, however it becomes unreadable for foreign reader. This is because these characters are encoded in a format that depends on the language used (if you're unfamiliar with the concept of code page, have a look at this article on Wikipedia). Unicode source files would not have this problem, all comments would be readable regardless of the default language chosen by the reader.
Translated strings
Many programs offer a choice between languages to use when installing or executing. This makes them more accessible to users unfamiliar with English. There is unfortunately no easy way to write strings and their translated versions in Eiffel program. For instance, programs targetting windows must create resource (.rc) files that aren't directly usable, and these .rc files aren't unicode. Unicode source files would offer the possibility to directly create and initialize localized strings, assuming proper classes become available to support that.
Operators
Free operators could be single unicode characters, like ∑ or ∩. Existing character combinations could be better displayed with a single unicode character:
- ↠instead of :=
- « and » instead of "[ and ]" (the most commonly used manifest string markers)
Existing support
EiffelStudio already includes classes to manipulate unicode strings, in the "encoding" library. However, each programmer must implement the code to read and write files in one of the unicode formats, convert the string and then use it.In practice, it's not hard to write applications that are properly localized, and use unicode strings. But it could be easier with direct support of unicode in the source code.
Solutions
A simple mechanism could be use to allow unicode characters in source files while remaining backward compatible. Currently, each file can be considered as using an informal code page that depends on the language used by the programmer, in strings and comments. By adding a note associated to the class, this code page can be made explicit:
One of the code page can be UTF-8. This format allows encoding of any unicode character while remaining compatible with most of the ASCII characters. A source file encoded using UTF-8 with only English strings and comments will be identical to its ASCII counterpart.Then EiffelStudio can have a setting indicating which code page to use by default, one of them being UTF-8. This enables everyone to keep their source code unchanged, or move to UTF-8 while keeping their old code unchanged if they add the note.
With this mechanism, new source files containing strings and comment in UTF-8 are compatible with versions of EiffelStudio not supporting unicode, old source files remain compatible with new versions of EiffelStudio, and if old/new files are mixed, they can all be displayed correctly thanks to the note clause.
There remains the problem of free operators and other symbols used in the language. A solution to this problem consists of encoding unicode characters using valid characters for free operators, for instance:
- Encoding ↠with :=
- Encoding « with "[ and » with ]"
- Encoding ∑ with |+|
Since the set of ASCII characters for free operators is limited, if we don't want long sequences it would be a good idea to restrict unicode characters usable for free operators in a first implementation, then specify how they are encoded. If this becomes a standard, then every sequence of characters used for free operators today can be displayed using its unicode counterpart. I believe the Eiffel community is small enough to agree on a common representation of unicode free operators, and to modify existing source code to make them look better if they want to.
The good news is that in 6.7, the compiler will accept UTF-8 source code, STRING_32 manifest string and Unicode free operators.
This is good news, I've wanted to use the correct Greek letters in some of the math algorithms I've implemented but have had to use their English phonetic versions.