ISO-8859 is dead, long live ISO-8859
- Tags:
- tutorial
- Article
- I18n
- Unicode
- Intermediate
- UTF-8
- memory
- characters sets
- internationalization
- ISO-8859
- ISO-8859-1
- ISO-8859-15
- latin
- latin-1
- Windows 1250
The Trade-offs of Unicode
Whilst Unicode has given us the wonderful gift of complete coverage of just about every written language in a single application, it has not come without a price. That price is the greatly increased amount of memory required to store 32 bit characters. If your application is mainly being used with single byte character sets, there are 3 bytes containing zero for every byte containing character data. If before the event of Unicode your search engine application ran on 5 machines, it now needs 20 machines. This fact has generally not been noticed much because of the impact of Moores law as related to memory, and the wide adoption of 64 bit architectures giving access to very large amounts of memory on a single machine.
Memory Conservation on Mobile Platforms
Conserving memory is particularly important on mobile platforms. This is because in a memory constrained environment, garbage collection performance degrades exponentially. The following chart is from a paper by Matthew Hertz and Emery D. Berger titled: Quantifying the Performance of Garbage Collection vs. Explicit Memory Management
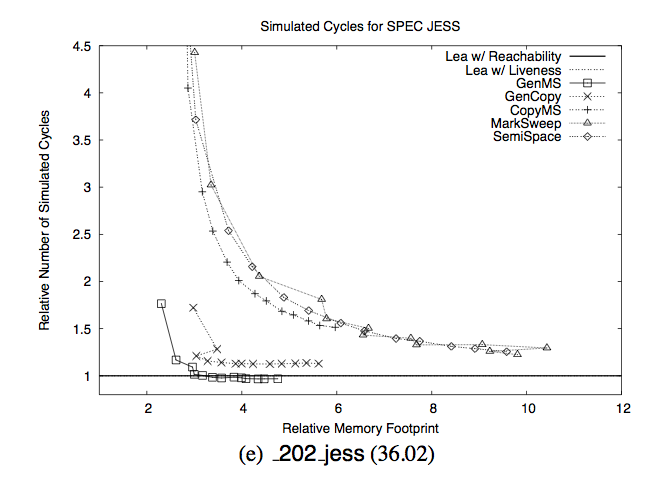
The Y axis is time spent collecting garbage. The X axis is the memory footprint relative to the minimum amount of memory required. What it says is that if you have less than twice the amount of required memory, you begin to see an exponential degradation in performance. For more details I would refer the reader to Drew Crawford's article Why mobile web apps are slow. In it he discusses why garbage collected languages are at a big disadvantage in Mobile apps and why Apple have deprecated garbage collection for iOS development in favor of ARC memory management. It's quite a long article so you may wish to skip down to the relevant section "GC on mobile is not the same animal as GC on the desktop".
I suspect that currently there is not a lot of Eiffel development being done for for Mobile, but it is only a matter of time before this changes.
UTF-8
Recognising that many would object to paying this price, the proponents of Unicode came up with UTF-8. UTF-8 uses memory efficiently by encoding characters coinciding with the ISO-8859-1 character set, as a single byte. Any other characters are encoded as an escaped multi-byte sequence. Cyrillic and other phonetic alphabets still require at least two bytes for each character.
However the benefits of UTF-8 do not come for free. Processing UTF-8 strings requires a significant amount of extra processing. This is because the start index of each single/multi-byte character in a UTF-8 sequence is unknown at the start of each routine and has to be calculated anew each time. As the attached benchmarks demonstrate, UTF-8 string operations take on average, more than 7 times longer to execute. For this reason UTF-8 is best suited as a format to store Unicode strings in a text file or database. If execution performance is critical in your application it is better to use 32 bit strings.
The Trade-offs of ISO-8859
The advantage of using latin character sets (LCS) is of course you can use single byte strings which are both fast and have the smallest memory footprint. But sooner or later you will face some problems. There is always some uncooperative user who wants to enter a Trademarkâ„¢ symbol in your application, or worse, quote a Russian proverb. Now your application is broken unless you have written some code to prevent the user from entering or importing characters foreign to the character set you are using.
The other major problem is that once you have committed to using LCS it is very difficult to change your application to Unicode should you change your mind.
Riding Two Horses
As they say in Hungary, it is impossible to ride two horses with one butt, but as regards Unicode and Latin, that is ideally what we would like to do. And thanks to the unlimited flexibility of software there is a way to ride two horses.
Introducing Augmented Latin Strings
Eiffel-Loop introduces a new type of string class called an Augmented Latin String (named EL_ASTRING). AL strings are single byte strings encoded using ISO-8859 character sets but augmented on the fly by Unicode characters whenever a particular character is lacking in the Latin set. This is made possible by using a trick based on the fact that there are 26 control characters in every Latin character set which are seldom if ever used. (Codes 1 to 8 and 14 to 31) These codes are employed as indices into a small table of Unicode characters stored as a character array. This technique allows inclusion of incidental characters like the Trademark symbol or even a small quote from a foreign language in a string primarily encoded using a Latin character set. To give an example.
The string "Oracleâ„¢" contains the trademark symbol in the last position. This is represented by the Unicode sequence:
{79, 114, 97, 99, 108, 101, 8482}
Class EL_STRING stores this internally by using two sequences
{79, 114, 97, 99, 108, 101, 1} + {8482}
The first sequence is stored using the array type: SPECIAL [CHARACTER], and the second using SPECIAL [CHARACTER_32]. If you add a second trademark symbol to the string, the size only increases by a single byte.
In class EL_ASTRING, the extra characters are stored in an attribute 'foreign_characters' which by default is assigned to a shared empty array. For the majority of strings, 'foreign_characters' will be empty, in which case EL_ASTRING can use the same string processing routines as STRING_8. If 'foreign_characters' is empty, the only extra memory required is for a reference pointer.
{EL_ASTRING}.codec
Class EL_ASTRING has a shared attribute of type EL_CODEC. The codec is used to convert from Unicode to various Latin character sets (and back again to Unicode) and is set globally for an application. Currently EL_ASTRING has implementations for the following codecs:
ISO-8859 Codecs
Sets numbered 1 to 15.
Windows Codecs
Sets numbered 1250 to 1258.
Compiling a Pure Unicode Application
The real beauty of using EL_ASTRING is that if decide you need a fully unicode compliant application to handle Asian character sets, all you have to do is recompile your application with a different implementation of EL_ASTRING that inherits from STRING_32 instead of STRING_8. This should work so long as you only initialize EL_ASTRING instances from unicode and were careful to call 'to_unicode' when passing the contents of an AL string to a routine that expects unicode. Any element changing routines of EL_ASTRING that takes an argument of type other than EL_ASTRING, assumes that the other string is encoded as unicode.
This technique has not yet been tested in the real world, but I can't think of any reason why it should not work.
Including Control Characters
Control Characters in AL strings still have their normal meaning and function providing that there are no extra unicode characters being stored in the string. You can test for this using 'has_foreign_characters'.
Over Extending
If you try to append too many characters foreign to the character set, you will use up the 26 available place holders. This is the biggest limitation of AL strings. In case of over extension the last place holder is set to the unicode replacement character '�', and any unencodeable characters are set to this. You can test for over extension with the query 'has_unencoded_characters'.
You are most likely to run into this problem with document length strings. If this happens then try modelling the document as a list of AL strings instead. You can then for example, quote Chinese in one paragraph and Russian in another, where the main character set is Roman based. But you must still be careful that each quote does not use more than 26 distinct characters.
Real World Examples
AL strings are already being used in a significant multi-lingual application called My Ching. My Ching is a search engine and journaling application for people who use the I Ching.
Many utilities and libraries found in Eiffel-Loop have already been converted to use AL strings.
STRING_8 Routine Coverage
At present only the most commonly used string routines from STRING_8 have been modified for use with EL_ASTRING. It may take some time to provide complete coverage.
EL_ASTRING Benchmarks
The performance of EL_ASTRING has been tested against STRING_32 and UC_UTF8_STRING using two different codecs. (Latin-1 and Latin-15)
Data Set
The test data is a database of pan-European IT job adverts, approximately 9 mb in size and comprising a mix of European languages: English; German; Spanish; Dutch; French and Swedish. The text has a liberal sprinkling of intentionally added Euro signs and Trademark symbols. The data is loaded as an arrayed list of 73000 Unicode strings (ARRAYED_LIST [STRING_32]), and passed to instances of the generic class TEST_STRINGS.
In case garbage collection skews the results, a full garbage collect is forced at the end of each test.
Test Routines
set_string_list
Initializes the list of test strings from the 32 bit unicode list.
set_lower_case
Changes case of each string to lower.
split_into_words
Splits each string into words and stores in a list of word lists.
set_unique_words
Compiles a set of unique lower case strings from the word lists.
quick_sort
Sorts the unique words using the quick sort algorithm.
remove_words_from_head
Takes a copy of each string and removes words from the left until it's empty.
append_words
Rebuild a copy of each string from the word lists.
prepend_words
Rebuild a copy of each string in reverse order from the word lists.
count_integer_words
Counts the total number of test strings which are integers.
count_occurrences_of_and
Counts all the occurrences of the string "and" across all test strings using the routine 'substring_index
to_unicode_32
Converts all original test strings back to 32 bit Unicode (STRING_32).
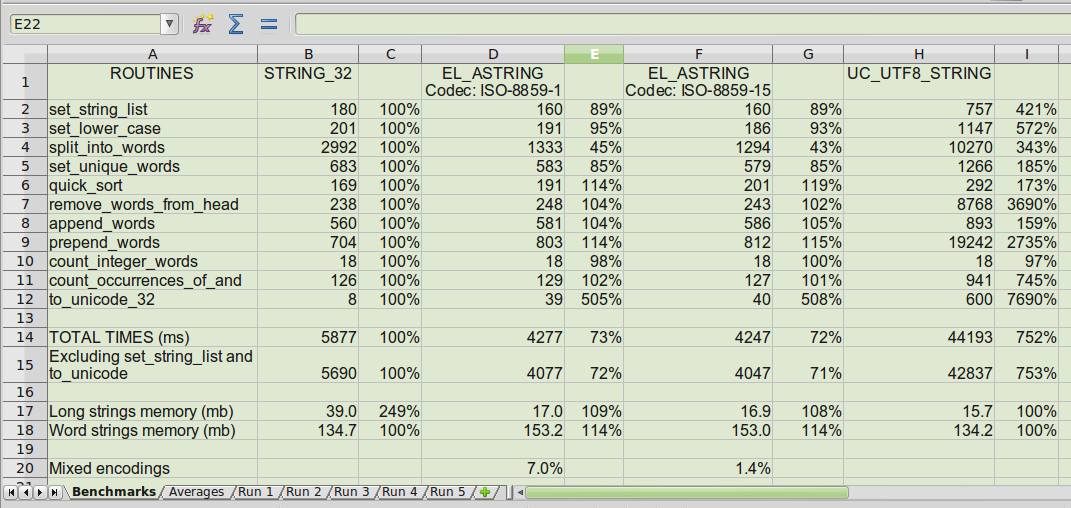
Benchmark Spreadsheet
These are the results of the benchmark tests averaged over 5 runs. The full spreadsheet is available in project download (see end). Each test has a relative performance figure that is relative to the STRING_32 time. The relative memory figures are relative to UC_UTF8_STRING.
The "Long strings memory" figures relate to the total memory required to store the headings and paragraphs of the job adverts. The "Short strings memory" figures relate to the resulting word strings from the 'split_into_words' routine.
The "Mixed encodings" figure relates to the percentage of AL strings that need to be augmented with unicode characters. The reason that AL strings using the ISO-8859-1 codec has a higher percentage, is because it lacks the euro symbol.
Comparison to STRING_32
Overall EL_ASTRING is about 28% faster than STRING_32 but certain operations are slower. The basic optimisation strategy for all routines is to first check if the object or routine arguments have foreign unicode characters. If not, it uses the STRING_8 routine, otherwise a modified version is called. Because most strings will not need to be augmented with unicode, a high percentage of calls will be to the fast STRING_8 routines.
Sorting is slower because when making comparisons between characters you have to compare like with like, unicode with unicode and latin with latin. This necessitates detecting place holders and doing some encoding conversions for characters having different encodings.
Appending or removing words is marginally slower because in those cases where the strings contain place holders, the ordering of the place holders has to be normalized to ensure a fast 'is_equal' query. It might be possible to do away with normalisation, except as a memory saving measure in the case of substrings, but this requires more research.
Long AL strings have an approximately 140% smaller memory footprint than STRING_32. For short word strings, STRING_32 has 14% smaller footprint. This is because regardless of whether is has any foreign characters, AL strings must still maintain an extra reference pointer. For a 64 bit architecture this will be an extra 8 bytes per string.
One quite surprising thing is that the initialization of the AL strings from unicode is 12% faster despite the fact that the routine {STRING_32}.make_from_string is just a character array copy.
Comparison to UC_UTF8_STRING
For long strings, EL_ASTRING uses on average only 8% more memory than UC_UTF8_STRING but executes in approx. 90% less time on average. For short word strings, EL_ASTRING uses 14% more memory.
A Brief Guide to Using EL_STRING
AL strings can be thought of as a way to smuggle the efficiencies of Latin character sets into a predominantly Unicode environment. Al strings are intended to be implicitly encoded back and forth from Unicode where using the defined conversions to and from STRING_32.
Suitability
AL strings is best suited for applications where the vast majority of the text data is encodable using a single latin character set. The unicode capability is there purely to cover exceptional circumstances where text from a foreign character set is quoted or some special unicode symbol is required in a particular document or paragraph.
Codec Selection
For Western languages, the recommended set to use is Latin-15 as it offers the most complete coverage. For other phonetic alphabets like Cyrillic for example, the appropriate codec can be set during application initialization based on the system locale using the routine {EL_SHARED_CODEC}.set_codec. Codecs are provided for all the major phonetic alphabets. (Latin sets 1 - 15)
Diverse Alphabets
If your application is required to store and manage a mix of long† tracts of text encoded with diverse phonetic alphabets, then you need to keep track of which codec was used to encode which string and switch codecs accordingly. There is no automatic way to do this. If this leads to overly complicated code then it may be preferable to use STRING_32 instead.
† long means more than 26 distinct characters.
Document Length Strings
It is better to avoid using AL strings for document length strings as it is easy to imagine a scenario where a user might input a number of quotes using different foreign alphabets. This carries the danger that the per string limitation of 26 distinct unicode characters is exceeded and you will end up with encodable characters in the string.
It is recommended instead to model documents as a list of AL string paragraphs and headings. It is assumed that quotations in more than one foreign alphabet occurring in the same paragraph is a very low probability event.
Double Byte Character Sets
Basing your application on AL strings does not necessarily preclude your application from being able to handle Asian character sets requiring at least 2 bytes per character. An alternative implementation of EL_ASTRING based on STRING_32 can be substituted in a recompile to turn your application into a full unicode applcation. The main proviso is that all your AL strings are initialized from Unicode, and routines expecting unicode arguments are satisfied by calling 'to_unicode' on AL strings.
Latin-1 as a Special Case
Using AL strings with the Latin-1 codec is a special case were the AL string is effectively the same as a unicode string and can be passed to unicode routines expecting a READABLE_STRING_GENERAL. This is because Latin-1 is a subset of the Unicode character set.
Downloads
Here you can find the full source code for EL_ASTRING and supporting classes, as well as the bench mark code, a test suite class, and the benchmark spreadsheet. EL_ASTRING-benchmarks-and-source-code.zip
If I understood well the main constraint
> If you try to append too many characters foreign to the character set, you will use up the 26 available place holders. This is the biggest limitation of AL strings
It seems this is not suitable for unicode text (i.e big text using more than 27 non ascii characters). What is a typical use case for AL strings? Small text like interface names?
As noted in your article, if one need full unicode support, you just need to recompile using implementation based on STRING_32, but then you loose all the potential benefit from AL strings. I guess it would be better to choose at compilation time the "default" implementation, but still be able to use the 2 implementations in a same application. This way, when you create an AL string, if you know it will use more than 26 unicode char, you would instantiate an AL string using the "String 32" implementation.
This sounds an interesting approach for small text (words, ..), but for specific usage, I am not sure I would want to use this by default. I may have missed some details, so don't hesitate to correct my words.
Big text
> It seems this is not suitable for unicode text (i.e big text using more than 27 non ascii characters).
I should point out the the Western ISO character sets have considerably more characters than the ascii set (unless you really meant latin-1)
AL string suitability
Hi Joceyln in response to your comments I have added a new section to my article "A Brief Guide to Using EL_STRING". I have also supplemented the section "Over Extending".
In brief I would use STRING_32 for document length strings and AL strings for paragraph length. There is no reason why you can't use both in the same app. The alternate implementation of EL_ASTRING is to enable Asian (non phonetic) double byte characters that are not translatable to any single byte scheme. With double byte (and more) characters, STRING_32 instances no longer seem so inefficient in terms of memory use. The slightly longer processing times can't be helped.
regards Finnian